Where does your software engineering team sit on the AI maturity curve?
Most engineering teams think they're AI-native. The data says otherwise. In fact, there could be a growing gap between frontier engineers and the rest of the pack. Here's how to figure out where you really are — and what it takes to level up.
The Uncomfortable Truth About AI Adoption
Here's a stat that should make every engineering leader pause: a small 2025 randomised controlled trial by METR found that experienced developers using AI tools were 19% slower than those coding without them. What was really strange in the study was that those same developers believed they were 24% faster. They were wrong about both the direction and the magnitude.
This isn't an argument against AI. It's an argument against how most teams are adopting it, and how their perceptions of their success adopting it can vary with reality.
Why did experienced developers get slower? The study doesn't isolate a single cause, but several factors likely contributed:
- Prompting overhead: Crafting effective prompts and iterating on AI output took longer than just writing the code
- Review friction: Verifying AI-generated code on an unfamiliar workflow added a new bottleneck
- Context switching: Bouncing between writing, prompting, and reviewing broke traditional workflows and flow states
- Miscalibrated trust: Developers spent time second-guessing correct output and accepting incorrect output
When does it flip positive? The METR study doesn't answer this directly — but the pattern across early adopters and the experiences across our technology work internally and with clients, suggests it happens when teams redesign workflows around AI rather than bolting it onto existing ones: narrower task scoping, richer context files, tight feedback loops, and proper evaluation systems. The study doesn't say AI is slow. It says unredesigned workflows are slow.
The organisations who are seeing real results experience 25-30%+ productivity gains. These aren't the teams that bolted GitHub Copilot onto their existing workflows and called it a day. They're the ones that fundamentally redesigned how their teams work. And the gap between those two groups is widening fast.
The rest of this post is about how to close that gap and leverage the recent gains in AI models for software engineering.
The 5 Levels of AI Maturity in Engineering Teams
Dan Shapiro, CEO of Glowforge, developed a framework that maps where teams actually sit on the AI adoption curve. It's become one of the clearest lenses for understanding the maturity gap — and it forces honesty from teams who work with it.
📋 Quick Self-Assessment: Where Does Your Team Sit?
Use this scorecard to place your team honestly. For each level, ask the diagnostic question — if you can't answer "yes" with evidence, you're probably not there yet.
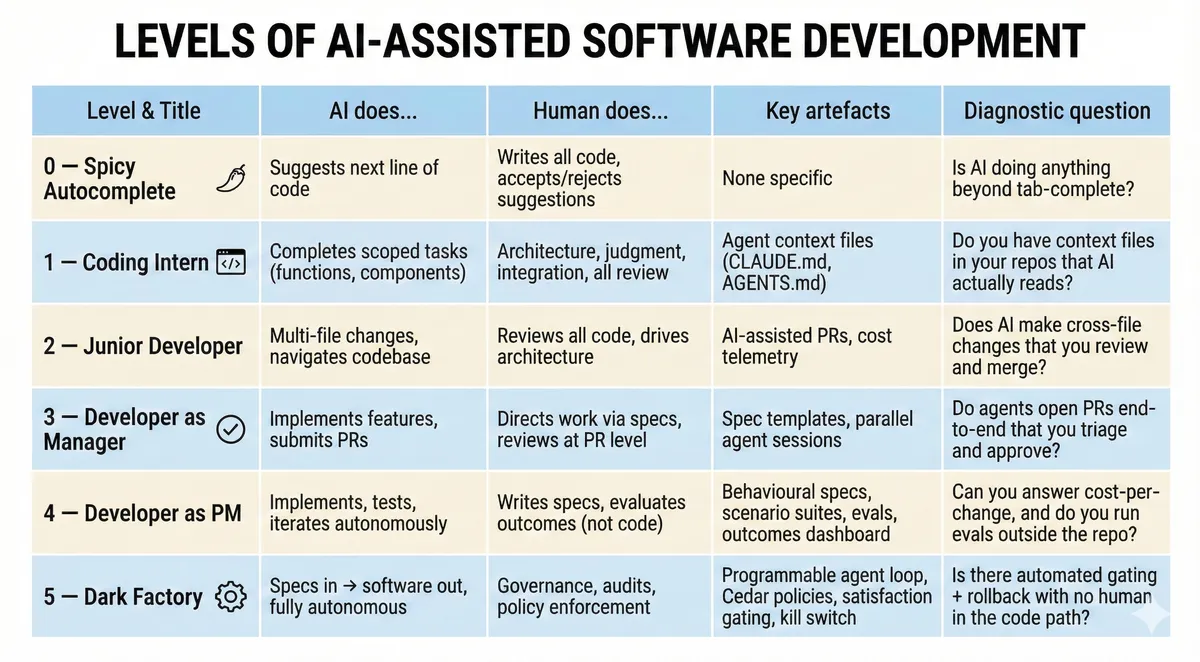
Level 0: Spicy Autocomplete
You type code. AI suggests the next line. Accept or reject. This is GitHub Copilot or tab complete from Cursor in its original form. The human writes software; AI reduces keystrokes. This is where most teams start.
Who's here: This is still the default experience for most developers using GitHub Copilot's original inline suggestions or Cursor's tab-complete. It's faster typing, but it's still typing.
Level 1: The Coding Intern
You hand AI discrete, well-scoped tasks: write this function, build this component. The human still handles architecture, judgment, and integration. AI is a capable assistant — but the engineer is doing the thinking.
Who's here: Teams here are starting to get a handle on the growing ecosystem of agent context files (e.g., claude.md, AGENTS.md). Teams add project conventions and boundaries to their repos so AI can handle scoped tasks more reliably. Good resources include Builder.io published a practical guide to writing effective AGENTS.md files, and the community-curated awesome-claude-code repo collects templates, skills and examples.
Level 2: The Junior Developer
AI handles multi-file changes, navigates the codebase, understands dependencies. The human still reviews all the code.
This is where most developers who describe themselves as "AI-native" are operating.
This is where major gains occur but is also the comfort zone. It feels exceptionally productive. The pull requests are flowing. But the fundamental workflow hasn't majorly changed.
Who's here: This is where most teams using Cursor, Cline (58k+ GitHub stars), or ChatGPT-assisted coding appear to sit today. Developers are pairing with AI across files and getting into flow states — but still reviewing every diff. Devin customers often start here too, using AI agents for repetitive migration tasks like Java upgrades and dependency bumps, with engineers reviewing all output before merge.
Level 3: Developer as Manager
This is where the workflow flips. The engineer is no longer writing code with AI help. Instead, the workflow involves directing AI and reviewing at the PR level. The model does the implementation and submits pull requests. The engineer manages the output.
It's possible for some developers to top out here. The psychological difficulty of letting go of code is real - people love this part of the job and it's akin to an artisanal craft for some.
Who's here: OpenAI's Codex is operates exceptionally well at this level and the next level, level 4. Engineers on the Codex team have stated they can run four to eight parallel agents simultaneously — one implementing a feature, another doing code review, a third running a security audit, a fourth summarising codebase changes. Context engineering is the key unlock: Codex reads AGENTS.md files for project conventions, and the team has built 100+ reusable "Skills". Devin's enterprise customers report similar patterns, with 6-12x efficiency gains when running multiple agents on isolated tasks in parallel.
Level 4: Developer as Product Manager
Write a specification. Walk away. Come back hours later and check if the tests pass. We are not reading code anymore — we are evaluating outcomes. The code itself is a black box. The key now is the system by which we set context, specs, ways of working, evaluations, and how we review code and improve the system by which we and the AI work.
Who's here: The frontier lab coding teams appear to be here. Boris Cherny, creator of Claude Code, hasn't personally written code in over two months. Internal teams at Anthropic report 70-90% AI-written code, with 90% of Claude Code's own codebase written by Claude Code itself. Shapiro himself says he operates here.
Level 5: The Dark Factory
Specs in, software out. No human writes code. No human reviews code. The factory runs autonomously with the lights off.
Almost no teams genuinely operate here today. You can count the publicly documented examples on one hand — and the gap between the marketing language and the operating reality across our industry is enormous.
Who's here: StrongDM's Software Factory remains the most thoroughly documented example. Three engineers have been shipping production software — 16,000 lines of Rust, 9,500 lines of Go, 700 lines of TypeScript — with no human code writing or review since July 2024. They've open-sourced key components: Attractor, Leash, and CXDB. Simon Willison's detailed write-up is a great overview. Cursor's FastRender experiment also offers a glimpse of what's coming: hundreds of autonomous agents coordinated to build a, somewhat working, web browser from scratch in under a week.
Adding to all of this is that the biggest org-wide gains come not from individual teams levelling up in isolation, but from sharing the artefacts across teams. Context file conventions, spec templates, eval harnesses, and policy frameworks are all expensive to build and cheap to reuse. An organisation with six teams independently at Level 3 — each with its own spec format and no shared eval infrastructure — is leaving compounding returns on the table. The exact 'best practices' for this new way of working, that fit your particular organisation, are also yet to be discovered - so encouraging sharing / peer review of what's working (and not), is key to success.
What Changes When the Human Stops Reading Code?
As teams move up the maturity curve, there's a critical inflection point between Level 3 and Level 5 that deserves its own framing. The shift isn't just about productivity. How do we build an engineering control system that replaces human code review with something more rigorous, not less?
When a human stops reading diffs, five things must be true:
- Quality controls must shift from review to evaluation. Teams replace "did someone read this?" with "did this pass a suite of behavioural scenarios, run N times, judged by an independent model?" The bar should be higher than manual review, not lower.
- Security must be policy-enforced, not trust-based. Prompt-level instructions ("don't access secrets") are replaced with kernel-level enforcement (the agent cannot access secrets). This is the difference between a guideline and a guardrail.
- Cost is a first-class metric. Without human oversight of every change, runaway token usage and compute costs can spiral. Every agent session needs a cost ceiling, and every change needs a cost-per-change metric.
- Auditability replaces visibility. Teams can't watch every agent session, but can log every tool call, file write, and shell command. Full provenance of - who requested what, which model produced it, what policies were in effect — are non-negotiable.
- Rollback becomes automatic. If a canary deployment regresses on any monitored metric, the system rolls back without waiting for a human to notice. The kill switch isn't a last resort — it's part of the normal operating loop.
Another way to think about this: going up the maturity curve isn't about sticking with the same controls. It's about replacing informal, human-dependent controls (code review, manual testing, tribal knowledge) with formal, machine-enforceable controls (policy engines, scenario suites, satisfaction gating, automated rollback). We are building the factory's assembly line from the ground up. The factory with the 'lights off' should have more safety infrastructure than the one with humans watching — not less.
Why Most Teams Are Stuck (and Don't Know It)
There's a pattern that plays out in almost every software engineering team adopting AI, and it follows what researchers call the J-Curve of AI adoption.
When you bolt AI onto existing workflows, productivity dips before it improves. The initial disruption — learning new tools, adjusting review processes, dealing with AI-generated code that's functional but architecturally naive — creates a temporary slowdown.
Some organisations are stuck at the bottom of this curve. And they're interpreting the dip as evidence that AI doesn't work.
The METR study captured this perfectly. Experienced developers on their own repos got slower because they were spending time prompting, reviewing, and correcting AI output within a workflow designed for human-only development. The tools weren't the problem. The workflow was.
Meanwhile, the teams pushing through the J-curve are seeing compounding returns. Look at the economics of AI-native companies:
- Cursor: ~$3.5M revenue per employee
- Midjourney: ~$5M revenue per employee
- Average SaaS company: $600K per employee
Even allowing for measurement differences, the top AI-native startups are running at roughly 5-6x the efficiency of traditional software companies. That's not marginal - it's a different operating model entirely.
Practical Steps to Level Up
So how do we move our teams up the maturity curve? Based on patterns emerging from early adopters including StrongDM's pioneering Dark Factory program, here's what actually works at each transition.
Moving from Level 0 → Level 1: Give AI Real Tasks
The shift: Stop using AI as autocomplete. Start treating it as a capable intern.
Create context files. Add a
claude.mdorAGENTS.mdto your repos with project conventions, build commands, test commands, and explicit boundaries for what AI should and shouldn't touch. This single step dramatically improves output quality.📝 Agent Context File Template (starter)
# Project: [Name] ## Build & Run - Build: `[command]` - Test: `[command]` - Lint: `[command]` ## Conventions - Language/framework: [e.g. TypeScript, React] - Style: [e.g. ESLint config, Prettier] - Naming: [e.g. camelCase for variables, PascalCase for components] ## Boundaries - DO NOT modify: [e.g. /config, .env files, auth module] - DO NOT install new dependencies without approval - Always run tests before committing ## Architecture Notes [Brief description of key modules, data flow, or patterns]
Start with well-scoped tasks. Function generation, component building, test writing. Give AI work with clear inputs and outputs.
Measure everything. Track time, tokens, and success rates from day one. You can't improve what you don't measure.
Moving from Level 1 → Level 2: Expand the Scope
The shift: Let AI handle multi-file changes and navigate your codebase.
- Invest in your codebase's AI-readability. Static types, clear naming, good documentation — these aren't just for humans anymore. TypeScript's move to become the first "agent-first" language isn't accidental. Strongly typed languages with fast feedback loops give AI the guardrails it needs to work across files reliably.
- Set up proper cost telemetry. You should be able to answer "what did that change cost?" for every AI-assisted change.
- Ship something small through the full pipeline. One real change, end-to-end, through your CI/CD, deployed to production. Make it tiny. Make it real.
Moving from Level 2 → Level 3: Change the Relationship
The shift: This is the hardest transition. You stop writing code with AI help and start managing AI that writes code.
Redesign code review. When AI generates the code, your review process needs to change. You're reviewing for architectural coherence, security implications, and alignment with specifications — not line-by-line correctness.
Train your team on specification writing. This is the new core skill. The quality of your specs directly determines the quality of your AI output. Vague specs produce vague code.
Build the specification habit. Create a standard spec template and make specs a first-class artefact, not an afterthought. A minimal starter:
📝 Spec Template (starter)
## Feature: [Name] ### Goal One sentence: what does this change accomplish? ### Non-goals What is explicitly out of scope? ### Constraints - Must/must not (security, performance, compatibility) - Dependencies and assumptions ### Interfaces - Inputs: what the agent receives - Outputs: what the user/system sees ### Acceptance Criteria - [ ] Criterion 1 (testable, specific) - [ ] Criterion 2 - [ ] Criterion 3 ### Red Flags Conditions that should halt or fail the task.
Address the psychology. Engineers who've spent years honing their craft will resist letting go. Acknowledge this directly. The skill isn't being replaced — it's evolving from implementation to direction.
Moving from Level 3 → Level 4: Evaluate Outcomes, Not Code
The shift: You can no longer read every diff. You need a quality system that doesn't depend on it.
Rewrite specs as behaviours, not implementation. Every spec should describe: what the user sees, what must never happen, and how to tell if it worked. This is now the primary input your agent optimises for.
Adopt scenario testing. Create a
scenarios/repo. A minimal template:📝 Scenario Template (starter)
## Scenario: [Name] ### Setup Preconditions and initial state. ### Action What the agent/system does. ### Expected Outcome - Primary: [what should happen] - Tolerance: [acceptable variance] ### Red Flags (auto-fail) - [ ] Data loss - [ ] Security violation - [ ] Performance regression > [threshold] - [ ] Unexpected external calls
StrongDM's factory uses end-to-end scenarios — closer to a holdout set than a unit test — stored outside the codebase so the agent can't overfit to them[1]. Create a scenarios/ repo where each scenario has: setup, action, expected outcome (with tolerances), and red flags (security, data loss).
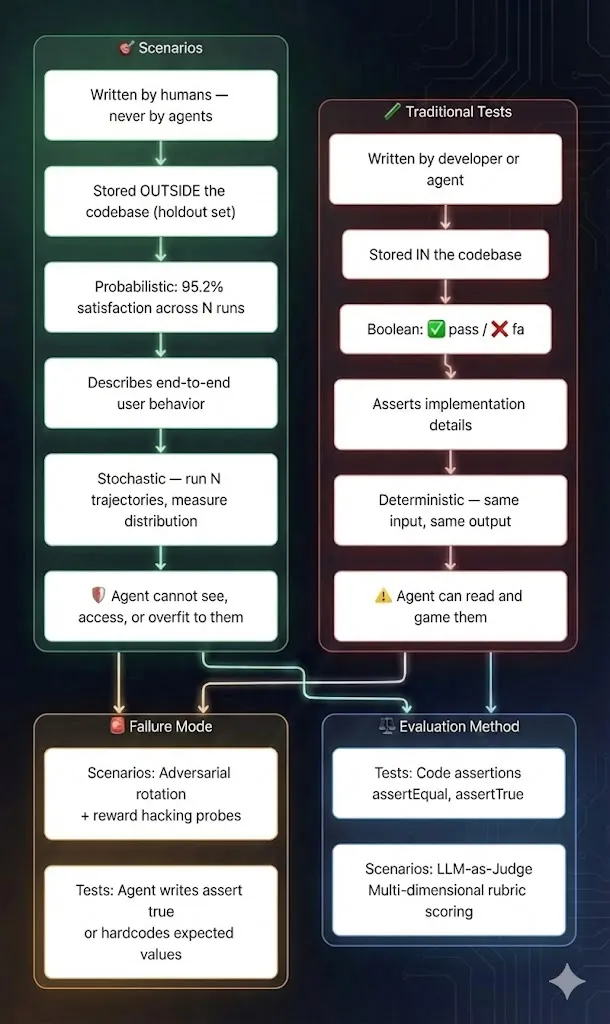
- Run scenarios many times. One pass isn't enough when you're not reading code. Run N trajectories and track pass rate, satisfaction rate (judge-based), worst-case outcomes, and drift over time.
- Make LLM-as-judge production-grade. Treat judges like measurement instruments, not oracles: benchmark against expert-labeled data, use ensembles to catch close calls, and track judge drift[2]. Crucially, use a separate model as judge — don't let the builder grade its own homework.
- Build minimal digital twins. Fast outcome-eval needs stable stand-ins for flaky dependencies (payments, auth, third-party APIs). Start with record/replay and contract tests. Measure twin fidelity nightly against production traces.
- Replace "read diff" with an outcomes dashboard. Give humans a review surface that isn't code: scenario results (what improved, what regressed), judge summaries with disagreement highlights, cost and risk reports.
- Run evals in CI as a flywheel. Analyse failures → add scenarios → improve specs → automate → repeat.[3]
This is the bridge where engineering becomes closer to product QA and safety engineering — making it hard for the agent to ship something wrong, without relying on a human reading the diff.
- Try the loop. The Ralph Wiggum technique — named after the Simpsons character and coined by Geoffrey Huntley — is the simplest possible way to experience the Level 4 mindset. In its purest form, it's a bash loop:
while :; do cat PROMPT.md | claude-code ; done. You write a spec, kick off the loop, and walk away. Each iteration is a fresh agent with clean context; progress persists through git history and files. A YC hackathon team shipped 6 repos overnight using it. - A word of caution: the technique is polarising. Critics flag real concerns — autonomous sessions can consume millions of tokens, produce large diffs that are difficult to review, and the quality of output depends entirely on the quality of your spec and termination criteria. Many developers are running it wrong, treating it as magic rather than a disciplined workflow. It's not a shortcut past the hard work of specification writing — it's a forcing function for it. Whether it becomes part of your workflow matters less than experimenting and understanding how it works. For our work - it's taught us something but has felt like a hack for anthropic harnesses, and we have used it less on Openai harnesses (Codex CLI, App) which we currently prefer.
Moving from Level 4 → Level 5: Going Dark
The shift: Remove human code review without removing control. This is less about trusting the model and more about building a factory where the model can't do anything unsafe.
- Start narrow. Pick a workstream with clear inputs/outputs, strong observability, low blast radius (internal tooling, migrations, feature flags), and a rollback story. Autonomy can scale — Cursor's FastRender proved that — but start where failure is cheap.
- Gate releases on satisfaction, not "tests pass". StrongDM's factory measures a probabilistic satisfaction score across N scenario trajectories, with scenarios kept out of the agent's view to prevent overfitting[1]. Set a threshold (e.g. ≥ 0.95) before anything ships.
- Use a programmable agent loop, not a CLI black box. StrongDM's Attractor spec explains why: a library-level loop lets you inspect between tool calls, log every shell command and file write, swap environments, and enforce invariants.
- Enforce policy at runtime, not just in the prompt. StrongDM's Leash wraps agents in containers with Cedar policies enforced at the kernel level. The difference between "the agent should not do X" and "the agent cannot do X." Forbid network egress by default, allowlist domains, restrict filesystem paths, block secrets access.
- Codify release as a deterministic contract. Machine-checkable criteria before anything deploys: satisfaction threshold, security scans, SBOM and provenance artifacts, canary metrics within bounds, automatic rollback on regression.
- Replace code review with governance. Going dark doesn't mean going blind. Weekly random sampling, monthly pipeline audits, quarterly external security reviews — and a real kill switch that halts all agent activity in one action.
The Junior Pipeline Problem
There's a downstream consequence of this shift that every engineering leader needs to grapple with. Junior developer job postings in the US have dropped 67%. UK graduate tech roles fell 46% in 2024, with projections of 53% by 2026.
The traditional apprenticeship model — where juniors learn by doing grunt work that AI now handles better and faster — is collapsing. The junior of 2026 needs systems design understanding that was expected of a mid-level engineer in 2020.
This isn't just a hiring problem. It's a pipeline problem. If we're not careful, we'll wake up in five years with a generation gap in our engineering organisations — plenty of senior engineers who grew up writing code, and no mid-levels who understand the craft deeply enough to direct AI effectively.
The teams investing in specification writing, systems thinking, and AI-native workflows as core training for new engineers are the ones building a sustainable talent pipeline.
How to Train Juniors in an AI-Native Org
The apprenticeship model isn't dead — it needs redesigning. I suggest replacing "write boilerplate and fix bugs" as the learning path for new joiners with:
- Specification writing. Juniors learn to decompose problems into clear, testable specs before any code is generated. This is now the foundational skill.
- System design drills. Understanding architecture, data flow, and failure modes matters more than ever when you're directing agents rather than writing implementations.
- Eval authoring. Writing scenario suites, defining acceptance criteria, and building test harnesses teaches juniors to think about quality at the system level.
- Red-team mindset. Juniors learn to break AI output systematically — finding edge cases, security holes, and logical errors. This builds the judgment that used to come from years of debugging.
- Context file ownership. Maintaining and improving
claude.md/AGENTS.mdfiles gives juniors deep exposure to codebases and conventions. - Guardrail design. Building and maintaining the safety infrastructure — policy files, gating criteria, rollback mechanisms — is meaningful work that teaches engineering discipline.
Give these juniors sandboxes to play with and ensure they deploy something real to production on their first day in the company. For these new joiners, we are teaching them the systems engineering methods of the future. The teams that figure this out first will have a talent advantage that compounds over years.
Where to Start
If you take one thing from this blog: don't assess your AI tools. Assess your AI workflows.
- Be honest about where you are. Walk your team through the 5 Levels. Most will say Level 3 or 4. But unless the evidence backs that up - it will be wrong. That gap is the starting point.
- Set the foundation, then raise the bar every sprint. Add a agents.md to your top repo today — project conventions, build commands, boundaries. It's the single highest-leverage starting point. Then make AI workflow improvement a standing agenda item: each sprint, pick one task the team still does manually that AI could own, run it through the agent, and record what worked, what broke, and what the spec was missing. Over weeks, your context files get sharper, your specs get tighter, and the level your team operates at quietly climbs. And build these as platform capabilities, not team-by-team efforts. A shared context file convention, a common spec template, and a reusable eval harness mean every team benefits from what any one team learns.
- Measure, compare, compound. Ship one real change through an agent end-to-end — not a demo, not a toy. Measure time, cost, and quality against your manual estimate. Then keep a simple scorecard: AI-assisted vs. human-only cycle time, rework rate, and cost per change. Review it monthly. The teams that move up the maturity curve fastest aren't the ones that make one big leap — they're the ones that run small experiments every week, feed the results back into better specs and context files, and let the gains compound. Continuous improvement isn't a mindset shift. It's a habit built one iteration at a time.
That's it. No major investment. No reorganisation. Undertake an honest self-assessment and implement a workflow that compounds learning and productivity every week.
The Bottom Line
The dark factory doesn't need more engineers. But it desperately needs better ones.
The teams that will thrive aren't the ones with the best AI tools. They're the ones who've redesigned their workflows, retrained their people, and are honest about separating how AI feels from hard facts around productivity.
The maturity curve is real. The J-curve dip is real. And the gap between teams that push through and teams that plateau is only going to widen.
The big question facing engineering teams, I'd suggest, isn't whether your team will adopt AI. It's whether you'll redesign your workflow around it.