No wall, just a firehose: A crazy week of frontier models and what it means for enterprise
TL;DR
The last week in AI has been ridiculous if you care about models:
- Google shipped Gemini 3 Pro (plus Nano Banana Pro / Gemini 3 Pro Image), and pushed it straight into Search (AI Mode), the Gemini app, Vertex AI and the Antigravity agentic IDE. Benchmarks put it at or near the top of the general-purpose pack.
- OpenAI rolled out GPT-5.1 (Instant & Thinking) and GPT-5.1-Codex-Max, a long-horizon coding model that can run multi-hour refactors and debugging tasks.
- xAI launched Grok 4.1, a frontier-class model tuned for emotional intelligence and creative work, with lower hallucination rates and aggressive pricing.
- Anthropic’s Claude Sonnet 4.5 / Haiku 4.5 spread across Microsoft Foundry, M365 Copilot, AWS Bedrock and Vertex AI, backed by an Azure + NVIDIA deal of up to ~US$30bn and ~1 GW of power.
- In open-weights, DeepSeek R1, Kimi K2, Qwen3 and Gemma 3 now form a credible GPT-4-class cluster, with very different licensing and geopolitical risk profiles.
The pace isn’t slowing, as we discussed previously, the innovation pace has been unprecedented this year. Pre-training is still buying capability gains; post-training (reasoning modes, RL, tools, safety) is where vendors now differentiate.
For enterprises, that means:
- “Best model” is now workload-specific, rather than vendor-specific.
- Cost-per-successful-task matters more now than just cost-per-token.
- Open-weights options are real and potentially valuable, but the “China question” around these models has shifted from a niche technical debate to a board-level risk discussion.
1. The week that was: four labs, one vision model and a lot of churn
1.1 Google: Gemini 3 is top of the class (but still hallucinates)
Gemini 3 Pro is now Google’s flagship underpinning multiple products including Search AI Mode, the Gemini app/API, Vertex AI and the new Antigravity IDE. It sits at or near the top of public leaderboards and posts state-of-the-art scores on GPQA Diamond, MMMU-Pro and Video-MMMU, with genuinely useful video understanding in day-to-day workflows.
The catch is that on Artificial Analysis’ Omniscience Index, Gemini 3 Pro has top accuracy but around 88% of its non-correct answers are hallucinations – if it doesn’t know, it often still guesses. By contrast, OpenAI reports ~2.8% hallucinations on FActScore and ~1–2% on LongFact for GPT-5, and Vectara’s leaderboard has Claude Sonnet 4.5 at ~5.5% hallucinations on short-doc summarisation. These models are much better at saying they don't know.
Potential applications:
- Use Gemini 3 as a multimodal/search workhorse with strong retrieval and UX (Google Search, Workspace, Cloud).
- Use GPT-5/5.1 or Claude for high-stakes factual work, with options to leverage Gemini behind a retrieval layer or for exploratory analysis.
In practice, most teams may eventually end up with Gemini for multimodal/search and GPT-5/Claude for low-hallucination factual workloads, rather than betting on a single “winner", but the landscape is moving rapidly.
Takeaway: I am finding Gemini great for rich retrieval, UX; and sticking to OpenAI/Anthropic where being accurate/repeatable matters.”
1.2 OpenAI: GPT-5.1 & Codex-Max – long runs, reliable, with major potential
OpenAI’s week was about reasoning and agents:
- GPT-5.1 (Instant & Thinking) is now the default ChatGPT/API model, using adaptive reasoning to spend fewer “thinking tokens” on easy tasks and more on hard ones.
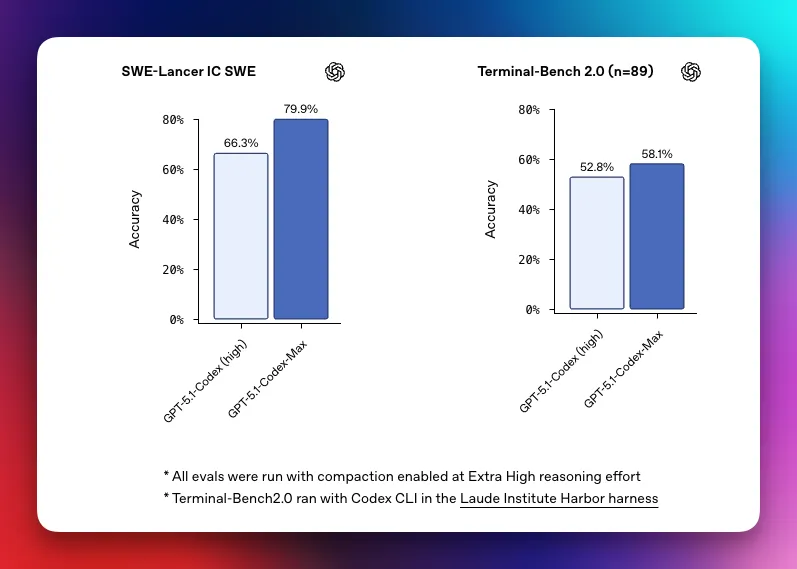
- GPT-5.1-Codex-Max adds history compaction and better coordination across multi-window tasks. OpenAI shows it working on a single refactor for over 24 hours in internal demos.
 OpenAI, Nov'25
OpenAI, Nov'25
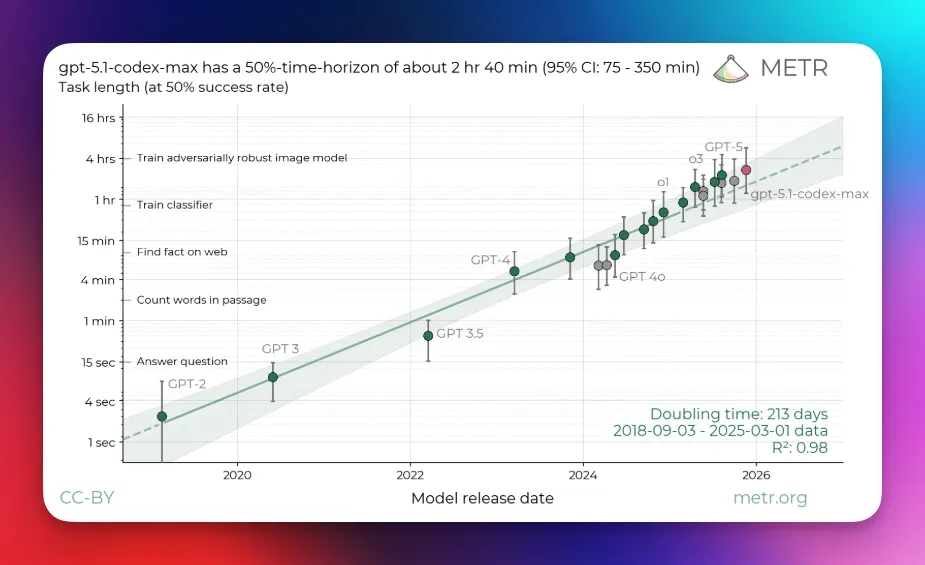
METR offers a more grounded view: for long-horizon software work, Codex-Max has a 50% “time horizon” of ~2h42, up from ~2h17 for GPT-5 – part of a smooth curve where that horizon has roughly doubled every 4–7 months since the o-series. Day-long reliable agents are still a few doublings away.
For CTO's:
- Codex-Max is a multi-hour engineer, ideal for refactors, deep debugging and migrations.
- It can offer 1–3 hour reliable runs today, with potential for 6–10 hours over the next few model cycles. We still need to keep humans/tests in the loop for critical work.
Google now leads on some most reasoning/multimodal benchmarks this week. Interestingly, reports claim that Gemini’s latest pre-training run “leapfrogged” GPT-5. But GPT-5/5.1 and Codex-Max still look best-in-class on factuality and long-horizon coding, which is what matters for most production use in the software development space.
Takeaway: In practice, initially I am leaning on GPT-5.1 (Thinking/Pro) for planning, GPT-5.1-Codex-Max for refactors and deep debugging, Gemini 3 for front-end and creative UX, and Claude Sonnet/Opus for security review and cyber risk work. But more testing over next few weeks / months will validate (or not) this approach.
1.3 xAI: Grok 4.1 – cheap, good EQ, use selectively
Grok 4.1 is xAI’s first truly frontier-class model. It ships in thinking and non-reasoning variants across grok.com, X and partner APIs, sits just behind Gemini 3 Pro on some LMArena views, and is tuned hard for emotional intelligence and creative writing.
Hallucinations are down from ~12% to ~4.2% for non-reasoning Grok 4.1, with FActScore errors around 3% – competitive with Claude and Gemini, still above GPT-5’s best factual scores. Pricing is the hook: public rates around US$0.20 / 0.50 per million input/output tokens in some channels are far below other frontier models.
Sweet spots:
- Customer-facing assistants and marketing where tone matters and retrieval/safety layers catch residual errors.
- A secondary “style layer” behind more conservative models for coding, analytics or regulated content.
Takeaway: Grok 4.1 is great when you want personality and low cost - good also as a secondary model for specific use cases.
1.4 Anthropic: Expanding access to Claude models
Anthropic didn’t ship a fresh model this week, but Claude Sonnet 4.5 and Haiku 4.5 are now everywhere:
- Available via Microsoft Foundry, Microsoft 365 Copilot (including Excel Agent Mode), AWS Bedrock and Google Vertex AI.
- Backed by a three-way Anthropic–Microsoft–NVIDIA deal that commits up to US$30bn of Azure spend and ~1 GW of power to future Claude training and inference clusters.
Sonnet 4.5 is great for coding and computer use (SWE-bench Verified, OSWorld, Terminal-Bench), in the same frontier tier as GPT-5.1 and Gemini 3 on general reasoning, with Gemini 3 Pro clearly ahead on the hardest multimodal and visual benchmarks.
Claude is among the most cloud-diversified frontier family, with a strong safety reputation and deep productivity-suite integrations, though its capacity and rate-limit policies are still evolving. If you’re already an M365 or AWS shop, Claude is a natural co-primary model alongside OpenAI or Gemini, especially for agents, spreadsheets and doc/slide drafting.
On safety, Anthropic is more forward-leaning in its model governance and catastrophic-risk frameworks than most labs, while OpenAI tends to be more conservative on day-to-day enterprise controls (data use, Agent Mode, tools). For CTOs, that means Anthropic is safety-forward in how it thinks about future models, but the practical execution risk from using Claude today is not clearly lower than with ChatGPT Enterprise.
Takeaway: Claude gives you reach and safety-forward model governance across clouds, but execution risk is not necessarily lower than OpenAI’s – you still need to manage agent security, rate limits and capacity as you scale.
1.5 Meta: SAM 3 – new vision capabilities
Meta’s contribution this week is a vision foundation model, a welcome distinction from the LLM focused week it was. Segment Anything Model 3 (SAM 3) is an 848M-parameter system that can detect, segment and track all instances of a concept in images and video based on short text prompts (“yellow school bus”, “player in a red jersey”) or visual examples.
 Sam 3 - Promptable Visual Segmentation
Sam 3 - Promptable Visual Segmentation
On Meta’s SA-Co benchmark (270k concepts, millions of instances), SAM 3 reaches about 75–80% of human performance and more than doubles prior open-vocabulary systems like OWLv2, DINO-X and even Gemini 2.5 on key detection metrics. A single model handles long video sequences and crowded scenes, maintaining consistent tracks across frames.
Meta also released SAM 3D, which reconstructs 3D objects and human bodies from a single image, useful for e-commerce spins, AR “view in room” experiences, digital twins and robotics. Both SAM 3 and SAM 3D ship with open weights and code, with an ecosystem forming around fine-tuning and annotation.
Enterprise use-cases:
- Redaction & compliance: text-prompted blurring of faces, plates or screens in CCTV/bodycam footage.
- Manufacturing & logistics QA: spotting damaged or mis-labelled items in line cameras.
- Retail & marketing: tracking product facings, editing images with precise segmentations.
- Vision front-ends for agents: giving Gemini/GPT/Claude agents object-level masks instead of raw pixels.
Takeaway: The enterprise opportunity is not just language – vision and 3D offer major opportunities to rethink workflows.
2. Pre-training vs post-training: no wall yet
Taken together, this week’s launches show that both pre-training and post-training still have meaningful headroom:
Pre-training: what this week shows
- Fresh large-scale pre-training runs like Gemini 3 Pro and Meta’s SAM 3 set new state-of-the-art results on hard benchmarks (GPQA Diamond, MMMU-Pro, Video-MMMU, SA-Co) compared with earlier generations, which is hard to explain without real gains in the underlying pre-trained models.
- New base families such as GPT-5.1 and Claude 4.5 also beat their prior generations on tough maths, coding and computer-use benchmarks (AIME, MathArena, LiveCodeBench, SWE-bench Verified, OSWorld) under broadly similar post-training recipes, again pointing back to stronger pre-trained representations rather than tuning alone.
- METR’s ~2h42 time horizon for Codex-Max continues a system-level trend where the 50% horizon roughly doubles every 4–7 months across model generations. That curve reflects a mix of larger, better pre-trained bases and smarter post-training/agent scaffolding, but when you pair it with massive new compute commitments (Anthropic’s Azure/NVIDIA deal, Google’s TPU v5p, NVIDIA’s Blackwell roadmap) there is strong evidence that labs will continue to see real returns from scaling pre-training.
Post-training & tools: where vendors really diverge
- Reasoning modes (GPT-5.1’s adaptive reasoning, Gemini’s Deep Think, Claude’s extended thinking, Grok’s EQ-tuning) are built via instruction tuning and RLHF, on top of the pre-trained base model.
- Agent frameworks (Codex-Max, Antigravity, Claude’s Agent SDK, Grok Agent Tools) depend heavily on tool-use training, safety constraints and scaffolding, which is where you see big differences in reliability and usefulness.
- Factuality and safety gaps – GPT-5’s low hallucinations, Gemini and Grok’s improvements, Claude’s work on deception/sycophancy – are mostly post-training plus eval discipline, and longer-term online RL over real user traces will likely decide who compounds fastest from real-world feedback.
Takeaway: Returns may be bending, but if current trends hold, enterprises should expect continued gains in core model intelligence, industry-tuned execution and longer, more reliable agent runs over the next year, pushing more workflows from "assistive" to genuinely automatable.
3. What this week means for enterprises
3.1 “Best model” is now a workload question
Rough guide going into 2026:
- Gemini 3 Pro: general chat, search-like UX and multimodal retrieval, especially on GCP and Google Workspace.
- GPT-5.1-Codex-Max & Claude Sonnet 4.5: long-horizon coding and deep debugging; Codex-Max looks stronger on long refactors, Claude on “use the computer” agents.
- Grok 4.1: emotion-heavy UX, conversational products, creative writing – and where cost really matters.
- Llama 3.1, Gemma 3, Qwen3, DeepSeek-R1 distils: open-weights options roughly in GPT-4-class, great when you need control or on-prem.
Takeaway: A repeatable and efficient approach is needed to validate “which model is best for this job**”.
3.2 Cost-per-token is now strategic
Patterns that are stable enough to plan around:
- Top closed models (GPT-5.1, Gemini 3 Pro, Claude Sonnet 4.5) stay premium: roughly US$1–3/million input tokens and US$10–15/million output tokens, depending on vendor/channel.
- xAI is undercutting everyone on frontier-grade reasoning with Grok 4.1 Fast around US$0.20 / 0.50 per million tokens.
- Open-weights models can be significantly cheaper at scale once you factor infra and ops, especially with smaller distilled variants and high utilisation.
For enterprises, the real metric is cost-per-successful-task: what you pay end-to-end to get work done to an acceptable standard. Tokens-per-watt and hardware efficiency matter for hyperscalers or those running their own clusters; everyone else feels them indirectly via pricing and capacity.
Takeaway: Model choice is about cost-engineering and capability-picking.
3.3 Architecture: Design for continual change
Given how fast the leaderboard rotates, three design principles to consider are:
- Abstract the model layer – put a gateway or internal abstraction in front of model calls so you can swap GPT-5.1 for Gemini 3 for Grok 4.1 for Sonnet 4.5 without rewriting half your stack.
- Route by workload – let coding agents favour Codex-Max/Sonnet 4.5; multimodal retrieval favour Gemini; low-stakes chat/marketing lean on Grok or open-weights. Don’t force everything through one endpoint.
- Version pin and test – pin model versions for critical workloads and maintain a small regression suite so you notice when post-training updates change behaviour.
Then align to your primary clouds:
- On Azure: OpenAI + Anthropic via Foundry/M365.
- On GCP: Gemini + Claude via Vertex AI.
- On AWS: Bedrock with Claude, Amazon Nova/Titan, and open models like Llama/Qwen and Mistral.
A regulated Australian bank on Azure, for example, might end up with:
- OpenAI + Claude for most internal apps,
- Gemini in a small GCP enclave for research/search-heavy workloads,
- Llama/Gemma/Qwen in its own VPC as cheap sub-agents.
Takeaway: Architecture should enable teams to plug models in and out without impacting business logic.
4. A note on open-weights vs closed models: where they actually fit
Open-weights models (often labelled “open-source”) have had a big year. The standouts: DeepSeek-R1/V3, Llama 3.1, Kimi K2, Qwen3, OpenAI's openweights models and Gemma 3.
On capability:
- Top open-weights such as Kimi K2 Thinking and gpt-oss-120b are now GPT-4+ to low-end GPT-5-class on many language and coding benchmarks.
- They still lag the leading closed models overall, particularly in multimodal capability, safety and robustness, even if Kimi K2 now ties or beats them on some specific reasoning benchmarks.
They’re a great fit when:
- You need data residency, fine-tuning or on-prem/VPC deployment.
- You can tolerate being 5–10 percentage points off the frontier in exchange for cost and control.
- You want cheap sub-agents inside a multi-model architecture.
They’re a more cautious fit when:
- You’re in heavily regulated public-sector or critical-infrastructure contexts and considering models that are already subject to government-device or public-sector restrictions in some Western markets.
- You need the very best available on multimodal reasoning or safety.
Takeaway: Use open-weights where control, sovereignty and cost win; closed models where peak capability and safety ecosystems win – and be explicit in your risk artefacts about jurisdiction and sovereignty risk for different model families.
5. Where this leaves you
If you’re running AI strategy, this week is a useful reset:
- Assume churn at the top. Gemini 3 Pro, Grok 4.1, GPT-5.1 and Claude Sonnet 4.5 can all claim “best” on some slice. That may not stabilise for some time.
- Architect for multi-model by default. Expect to mix 3–5 models across your estate and swap them over time. Align your API layer, security and observability with that reality.
- Treat pre-training and post-training as separate bets. Scale lifts the ceiling; post-training (RLHF, tools, safety, ORL) shapes behaviour, factuality and agent performance. When you pick vendors, you’re really choosing their post-training philosophy, not just their FLOPs.
- Be deliberate about open-weights and geopolitics. Open-weights are good enough to matter, and some of the strongest are Chinese. That doesn’t mean “don’t use them”, but it does mean conscious, documented decisions in regulated or government-adjacent sectors.
- Keep risk and finance close. Token prices, reasoning-effort settings, caching, time-horizon curves and power constraints are now economic variables, and regulators are increasingly interested in which models you use where, and why.
If it all feels like a lot, that’s normal for where we are in the cycle. The upside is that we’re still early. This week’s launches are one frame in what looks like what could be a decade-long reel of steady, compounding progress.
The trick isn’t to guess who “wins” the model war. It’s to build architecture, governance and skills that can ride the curve – whoever happens to be on top next quarter.